# Hive 优化
# 一、启用压缩
压缩可以使磁盘上存储的数据量变小,例如,文本文件格式能够压缩40%甚至更高比例,这样可以通过降低I/O来提高查询速度。除非产生的数据用于外部系统,或者存在格式兼容性问题,建议总是启用压缩。压缩与解压缩会消耗CPU资源,但Hive产生的MadReduce作业往往是I/O密集型的,因此CPU开销通常不是问题。
# 1.1 压缩格式
MR支持的压缩编码
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
查看群集开启了哪些压缩
hadoop checknative
压缩性能的比较
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| Gzip | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| bzip2 | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
WARNING
注意输出压缩并不适用所有文件格式,比如ORC就不需要以上设置。具体可以看我做的sequence 对比 orc测试。
# 1.2 压缩参数配置
要在 Hadoop 中启用压缩,可以配置如下参数(mapred-site.xml 文件中):
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs(在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用 LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
# 1.3 开启 Map 输出阶段压缩(MR 引擎)
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下:
- 开启 hive 中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
- 开启 mapreduce 中 map 输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
- 设置 mapreduce 中 map 输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
# 1.4 开启 Reduce 输出阶段压缩
当 Hive 将输出写入到表中时,输出内容同样可以进行压缩。属性 hive.exec.compress.output 控制着这个功能。用户可能需要保持默认设置文件中的默认值 false, 这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这 个值为 true,来开启输出结果压缩功能。
- 开启 hive 最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
- 开启 mapreduce 最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
- 设置 mapreduce 最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
- 设置 mapreduce 最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
- 测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory '/opt/module/data/distribute-result' select * from emp distribute by deptno sort by empno desc;
# 二、存储格式
# 2.1 支持的存储格式
Hive 会在 HDFS 为每个数据库上创建一个目录,数据库中的表是该目录的子目录,表中的数据会以文件的形式存储在对应的表目录下。Hive 支持以下几种文件存储格式:
| 格式 | 说明 |
|---|---|
| TextFile | 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2 使用,但使用 Gzip 这种方式,hive 不会对数据进行切分,从而无法对数据进行并行操作。 |
| SequenceFile | SequenceFile 是 Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用 Hadoop 的标准的 Writable 接口实现序列化和反序列化。它与 Hadoop API 中的 MapFile 是互相兼容的。Hive 中的 SequenceFile 继承自 Hadoop API 的 SequenceFile,不过它的 key 为空,使用 value 存放实际的值,这样是为了避免 MR 在运行 map 阶段进行额外的排序操作。 |
| RCFile | RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据按列存储,每一列的数据都是分开存储。 |
| ORC Files | ORC 是在一定程度上扩展了 RCFile,是对 RCFile 的优化。 |
| Avro Files | Avro 是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro 提供的机制使动态语言可以方便地处理 Avro 数据。 |
| Parquet | Parquet 是基于 Dremel 的数据模型和算法实现的,面向分析型业务的列式存储格式。它通过按列进行高效压缩和特殊的编码技术,从而在降低存储空间的同时提高了 IO 效率。 |
以上压缩格式中 ORC 和 Parquet 的综合性能突出,使用较为广泛,推荐使用这两种格式。
# 2.2 列式存储和行式存储
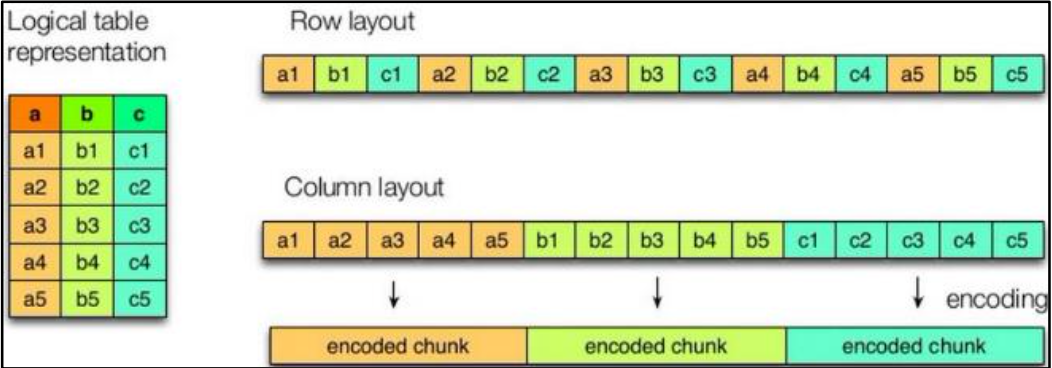
- 行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度 更快。
- 列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
# 2.3 Orc 格式
Orc (Optimized Row Columnar)是 Hive 0.11 版里引入的新的存储格式。 如下图所示可以看到每个 Orc 文件由 1 个或多个 stripe 组成,每个 stripe 一般为 HDFS 的块大小,每一个 stripe 包含多条记录,这些记录按照列进行独立存储,对应到 Parquet 中的 row group 的概念。每个 Stripe 里有三部分组成,分别是 Index Data,Row Data,Stripe Footer:
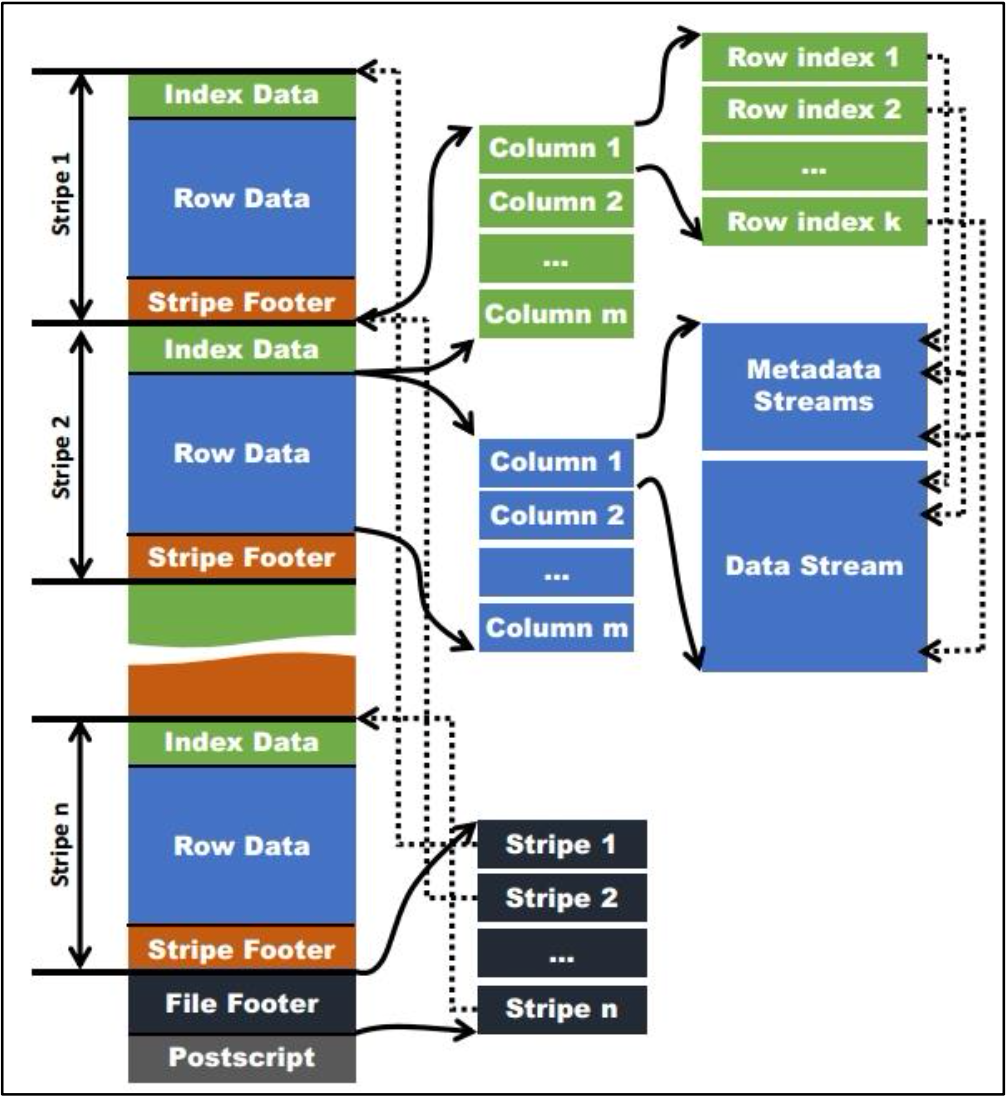
- Index Data:一个轻量级的 index,默认是每隔 1W 行做一个索引。这里做的索引应该 只是记录某行的各字段在 Row Data 中的 offset。
- Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个 列进行了编码,分成多个 Stream 来存储。
- Stripe Footer:存的是各个 Stream 的类型,长度等信息。
每个文件有一个 File Footer,这里面存的是每个 Stripe 的行数,每个 Column 的数据类 型信息等;每个文件的尾部是一个 PostScript,这里面记录了整个文件的压缩类型以及 FileFooter 的长度信息等。在读取文件时,会 seek 到文件尾部读 PostScript,从里面解析到 File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
# 2.4 Parquet 格式
Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的 数据和元数据,因此 Parquet 格式文件是自解析的。
- 行组(Row Group):每一个行组包含一定的行数,在一个 HDFS 文件中至少存储一 个行组,类似于 orc 的 stripe 的概念。
- 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连 续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的 算法进行压缩。
- 页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块 的不同页可能使用不同的编码方式。
通常情况下,在存储 Parquet 数据的时候会按照 Block 大小设置行组的大小,由于一般 情况下每一个 Mapper 任务处理数据的最小单位是一个 Block,这样可以把每一个行组由一 个 Mapper 任务处理,增大任务执行并行度。Parquet 文件的格式。
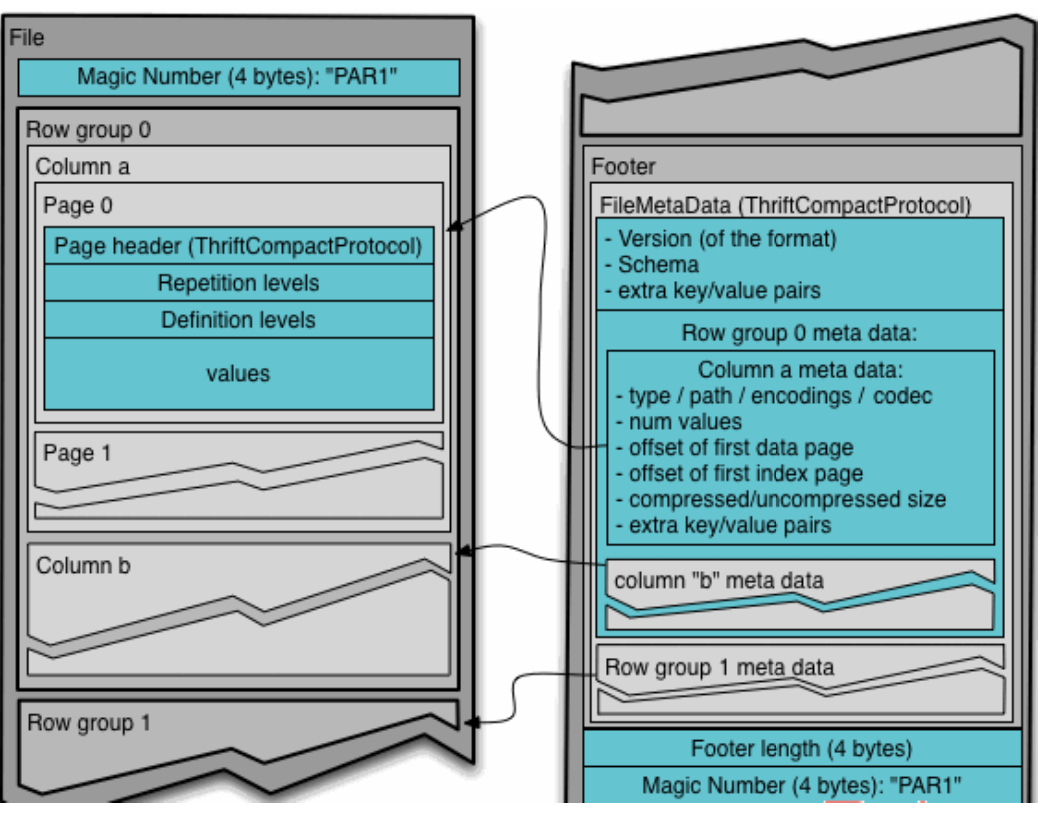
上图展示了一个 Parquet 文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的 Magic Code,用于校验它是否是一个 Parquet 文件,Footer length 记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的 Schema 信息。除了文件中每一个行组的元数据,每一 页的开始都会存储该页的元数据,在 Parquet 中,有三种类型的页:数据页、字典页和索引 页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最 多包含一个字典页,索引页用来存储当前行组下该列的索引,目前 Parquet 中还不支持索引页。
# 2.5 指定存储格式
通常在创建表的时候使用 STORED AS 参数指定:
CREATE TABLE page_view(viewTime INT, userid BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
2
3
4
5
6
各个存储文件类型指定方式如下:
- STORED AS TEXTFILE
- STORED AS SEQUENCEFILE
- STORED AS ORC
- STORED AS PARQUET
- STORED AS AVRO
- STORED AS RCFILE
# 2.6 Sequence 对比 ORC
群集磁盘资源紧张,需要对表数据进行压缩,将从Sequence、ORC中选其一作为以后仓库表文件的存储格式。本文就Snappy及ZLIB(Gzip)压缩级别进行表大小以及查询效率的对比
- 压缩参数
Sequence
-- Snappy
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
set mapred.output.compression.type=BLOCK;
-- Gzip
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compression.type=BLOCK;
2
3
4
5
6
7
8
9
10
11
ORC
-- Snappy
set hive.exec.orc.default.compress=SNAPPY;
-- ZLIB
set hive.exec.orc.default.compress=ZLIB;
2
3
4
5
- 大小对比
订单主表
| 格式 | 文件大小 | 占用大小 | 压缩比(倍) |
|---|---|---|---|
| text | 19.8G | 59.5G | |
| seq_snappy | 6.1G | 18.4G | 3.24 |
| orc_snappy | 4.2G | 12.5G | 4.71 |
| seq_gzip | 3.4G | 10.3G | 5.82 |
| orc_zlib | 3.0G | 9.0G | 6.6 |
订单明细表
| 格式 | 文件大小 | 占用大小 | 压缩比(倍) |
|---|---|---|---|
| text | 18.8G | 56.5G | |
| seq_snappy | 4.2G | 12.5G | 4.38 |
| orc_snappy | 2.6G | 7.8G | 7.23 |
| seq_gzip | 2.3G | 6.9G | 8.17 |
| orc_zlib | 1.7G | 5.0G | 11.05 |
- SQL查询效率
简单Count
| 格式 | 第一次 | 第二次 | 第三次 |
|---|---|---|---|
| seq_snappy | 23.16 | 21.813 | 23.031 |
| orc_snappy | 22.154 | 19.911 | 20.582 |
| seq_gzip | 33.362 | 26.446 | 27.537 |
| orc_zlib | 21.197 | 19.23 | 18.499 |
过滤并分组
| 格式 | 第一次 | 第二次 | 第三次 |
|---|---|---|---|
| seq_snappy | 27.436 | 26.453 | 27.796 |
| orc_snappy | 21.568 | 25.971 | 29.075 |
| seq_gzip | 35.16 | 78.649 | 38.198 |
| orc_zlib | 20.273 | 21.491 | 19.539 |
联查询Count
主表与明细表通过订单ID关联
| 格式 | 第一次 | 第二次 | 第三次 |
|---|---|---|---|
| seq_snappy | 64.336 | 68.128 | 63.755 |
| orc_snappy | 71.017 | 100.511 | 65.912 |
| seq_gzip | 98.201 | 79.246 | 79.736 |
| orc_zlib | 99.996 | 69.23 | 74.677 |
实际查询
主表与明细表通过订单ID关联,分组,单表select * , max ,sum等聚合
| 格式 | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 第六次 |
|---|---|---|---|---|---|---|
| seq_snappy | 580.938 | 1065.992 | 787.999 | 1365.383 | 622.456 | 605.303 |
| orc_snappy | 696.887 | 1333.952 | 1034.791 | 806.678 | 789.647 | 794.424 |
| seq_gzip | 806.734 | 1448.114 | 1237.069 | 901.431 | 901.75 | 854 |
| orc_zlib | 1983 | 1983 | 1294.967 | 906.825 | 926.922 | 975.837 |
第六次细节
| 类型 | Job | Stage | Map | Reduce | Elapsed | Vcore Map(Seconds) | Vcore Reduce(Seconds) | Vcore Total(Sedonds) | -(orc-seq)/seq |
|---|---|---|---|---|---|---|---|---|---|
| seq_snap | job_1583725051064_59160 | Stage-1 | 57 | 11 | 5mins,44sec | 1694222 | 2924159 | 4618381 | |
| orc_snap | job_1583725051064_59190 | Stage-1 | 49 | 7 | 8mins,45sec | 1494752 | 2895072 | 4389824 | 4.95% |
| seq_snap | job_1583725051064_59187 | Stage-2 | 38 | 10 | 4mins,8sec | 1193042 | 1820443 | 3013485 | |
| orc_snap | job_1583725051064_59198 | Stage-2 | 39 | 10 | 4mins,12sec | 1197185 | 1941388 | 3138573 | -4.15% |
| seq_gzip | job_1583725051064_59028 | Stage-1 | 49 | 6 | 9mins,39sec | 1667028 | 2851133 | 4518161 | |
| orc_zlib | job_1583725051064_59046 | Stage-1 | 48 | 5 | 11mins,24sec | 1477584 | 2937803 | 4415387 | 2.27% |
| seq_gzip | job_1583725051064_59043 | Stage-2 | 42 | 10 | 4mins,19sec | 1213325 | 2140155 | 3353480 | |
| orc_zlib | job_1583725051064_59065 | Stage-2 | 40 | 10 | 4mins,37sec | 1206666 | 2188277 | 3394943 | -1.24% |
| 类型 | Elapsed | Vcore Total(Sedonds) | -(orc-seq)/seq |
|---|---|---|---|
| seq_snap | 9mins,52sec | 7631866 | |
| orc_snap | 12mins,57sec | 7528397 | 1.36% |
| seq_gzip | 13mins,58sec | 7871641 | |
| orc_zlib | 16mins | 7810330 | 0.78% |
- 结论
- 以数据压缩后的大小来看,ORC完胜。
- SQL查询方面,因为orc的文件更小,所以map和reduce数相对较小,导致运算时间增长(20%左右),但总体CPU资源耗用还是要比Seq格式少1%左右。
# 三、优化连接
可以通过配置Map连接和倾斜连接的相关属性提升连接查询的性能。一般处理大量小表关联导致运行缓慢
# 3.1 自动Map连接(跨服务器广播小表的Mapjoin)
当连接一个大表和一个小表时,自动Map连接是一个非常有用的特性。如果启用了该特性,小表将保存在每个节点的本地缓存中,并在Map阶段与大表进行连接。开启自动Map连接提供了两个好处。首先,将小表装进缓存将节省每个数据节点上的读取时间。其次,它避免了Hive查询中的倾斜连接,因为每个数据块的连接操作已经在Map阶段完成了。设置下面的属性启用自动Map连接属性。
- 设置自动选择 Mapjoin
# 默认为 true,如果orc报错就要关掉
set hive.auto.convert.join = true;
2
- 大表小表的阈值设置(默认 25M 以下认为是小表):
set hive.mapjoin.smalltable.filesize = 25000000;
# 桶Map连接
如果连接中使用的表是按特定列分桶的,可以开启桶Map连接提升性能。
<property>
<name>hive.optimize.bucketmapjoin</name>
<value>true</value>
</property>
<property>
<name>hive.optimize.bucketmapjoin.sortedmerge</name>
<value>true</value>
</property>
2
3
4
5
6
7
8
说明:
- hive.optimize.bucketmapjoin:是否尝试桶Map连接。
- hive.optimize.bucketmapjoin.sortedmerge:是否尝试在Map连接中使用归并排序。
# 四、Group by 优化
默认情况下,Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时就倾斜了。并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行 部分聚合,最后在 Reduce 端得出最终结果。
- 是否在 Map 端进行聚合,默认为 True
set hive.map.aggr = true
- 在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
- 有数据倾斜的时候进行负载均衡(默认是 false)
set hive.groupby.skewindata = true
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出 结果会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果 是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二 个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证 相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
# 五、 Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个 Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成, 一般 COUNT DISTINCT 使用先 GROUP BY 再 COUNT 的方式替换,但是需要注意 group by 造成 的数据倾斜问题.
# 六、合理设置 Map 及 Reduce 数
- 通常情况下,作业会通过 input 的目录产生一个或者多个 map 任务。 主要的决定因素有:input 的文件总个数,input 的文件大小,集群设置的文件块大小。
- 是不是 map 数越多越好? 答案是否定的。如果一个任务有很多小文件(远远小于块大小 128m),则每个小文件也会被当做一个块,用一个 map 任务来完成,而一个 map 任务启动和初始化的时间远远大 于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的 map 数是受限的。
- 是不是保证每个 map 处理接近 128m 的文件块,就高枕无忧了? 答案也是不一定。比如有一个 127m 的文件,正常会用一个 map 去完成,但这个文件只 有一个或者两个小字段,却有几千万的记录,如果 map 处理的逻辑比较复杂,用一个 map 任务去做,肯定也比较耗时。
针对上面的问题 2 和 3,我们需要采取两种方式来解决:即减少 map 数和增加 map 数;
# 6.1 复杂文件增加 Map 数
当 input 的文件都很大,任务逻辑复杂,map 执行非常慢的时候,可以考虑增加 Map 数, 来使得每个 map 处理的数据量减少,从而提高任务的执行效率。 增加 map 的方法为:根据computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M 公式, 调整 maxSize 最大值。让 maxSize 最大值低于 blocksize 就可以增加 map 的个数。
-- 实例
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 1; number of
reducers: 1
-- 设置最大切片值为 100 个字节
hive (default)> set mapreduce.input.fileinputformat.split.maxsize=100;
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 6; number of
reducers: 1
2
3
4
5
6
7
8
9
# 6.2 小文件进行合并
- 在 map 执行前合并小文件,减少 map 数:CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat 没有对小文件合并功能。
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
- 在 Map-Reduce 的任务结束时合并小文件的设置:
-- 在 map-only 任务结束时合并小文件,默认 true
SET hive.merge.mapfiles = true;
-- 在 map-reduce 任务结束时合并小文件,默认 false
SET hive.merge.mapredfiles = true;
-- 合并文件的大小,默认 256M
SET hive.merge.size.per.task = 268435456;
-- 当输出文件的平均大小小于该值时,启动一个独立的 map-reduce 任务进行文件 merge
SET hive.merge.smallfiles.avgsize = 16777216;
2
3
4
5
6
7
8
# 6.3 合理设置 Reduce 数
- 调整 reduce 个数方法一
-- 每个 Reduce 处理的数据量默认是 256MB
hive.exec.reducers.bytes.per.reducer=256000000
-- 每个任务最大的 reduce 数,默认为 1009
hive.exec.reducers.max=1009
-- 计算 reducer 数的公式
N=min(参数 2,总输入数据量/参数 1)
2
3
4
5
6
- 调整 reduce 个数方法二
-- 在 hadoop 的 mapred-default.xml 文件中修改设置每个 job 的 Reduce 个数
set mapreduce.job.reduces = 15;
2
- reduce 个数并不是越多越好
(1)过多的启动和初始化 reduce 也会消耗时间和资源;
(2)另外,有多少个 reduce,就会有多少个输出文件,如果生成了很多个小文件,那 么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题; 在设置 reduce 个数的时候也需要考虑这两个原则:处理大数据量利用合适的 reduce 数; 使单个 reduce 任务处理数据量大小要合适;
# 七、启用并行执行
Hive 会将一个查询转化成一个或者多个阶段。这样的阶段可以是 MapReduce 阶段、抽 样阶段、合并阶段、limit 阶段。或者 Hive 执行过程中可能需要的其他阶段。默认情况下, Hive 一次只会执行一个阶段。不过,某个特定的 job 可能包含众多的阶段,而这些阶段可能 并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个 job 的执行 时间缩短。不过,如果有更多的阶段可以并行执行,那么 job 可能就越快完成。通过设置参数 hive.exec.parallel 值为 true,就可以开启并发执行。不过,在共享集群中, 需要注意下,如果 job 中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个 sql 允许最大并行度,默认为8
2
当然,得是在系统资源比较空闲的时候才有优势,否则,没资源,并行也起不来。
# 八、启用MapReduce严格模式
Hive提供了一个严格模式,可以防止用户执行那些可能产生负面影响的查询。通过设置下面的属性启用MapReduce严格模式。
<property>
<name>hive.mapred.mode</name>
<value>strict</value>
</property>
2
3
4
严格模式禁止3种类型的查询。
- 对于分区表,where子句中不包含分区字段过滤条件的查询语句不允许执行。
- 对于使用了order by子句的查询,要求必须使用limit子句,否则不允许执行。
- 限制笛卡尔积查询。
# 九、启用向量化
向量化特性在Hive 0.13.1版本中被首次引入。通过查询执行向量化,使Hive从单行处理数据改为批量处理方式,具体来说是一次处理1024行而不是原来的每次只处理一行,这大大提升了指令流水线和缓存的利用率,从而提高了表扫描、聚合、过滤和连接等操作的性能。可以设置下面的属性启用查询执行向量化。
<property>
<name>hive.vectorized.execution.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.vectorized.execution.reduce.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.vectorized.execution.reduce.groupby.enabled</name>
<value>true</value>
</property>
2
3
4
5
6
7
8
9
10
11
12
说明:
- hive.vectorized.execution.enabled:如果该标志设置为true,则开启查询执行的向量模式,默认值为false。
- hive.vectorized.execution.reduce.enabled:如果该标志设置为true,则开启查询执行reduce端的向量模式,默认值为true。
- hive.vectorized.execution.reduce.groupby.enabled:如果该标志设置为true,则开启查询执行reduce端group by操作的向量
# 十、内存溢出相关设置
Error: Java heap space
set hive.exec.parallel=true;
set mapred.max.split.size=128000000;
set mapreduce.map.memory.mb=6144;
set mapreduce.map.java.opts=-Xmx6144m;
set hive.exec.reducers.bytes.per.reducer=536870912;
set mapreduce.reduce.memory.mb=8192;
set mapreduce.reduce.java.opts=-Xmx8192m;
2
3
4
5
6
7
# 十一、避免使用order by全局排序
Hive中使用order by子句实现全局排序。order by只用一个Reducer产生结果,对于大数据集,这种做法效率很低。如果不需要全局有序,则可以使用sort by子句,该子句为每个reducer生成一个排好序的文件。如果需要控制一个特定数据行流向哪个reducer,可以使用distribute by子句,例如:
select id, name, salary, dept from employee
distribute by dept sort by id asc, name desc;
2
属于一个dept的数据会分配到同一个reducer进行处理,同一个dept的所有记录按照id、name列排序。最终的结果集是全局有序的。
我们也可以使用CLUSTER BY它具备DISTRIBUTE BY 和 SORT BY的功能,但是只能正序排序。无法指定倒序。算是上面查询的精简版。
SELECT s.emp_id,s.emp_name,s.emp_mobile,s.city
FROM employee3 s
CLUSTER BY s.city;
2
3
# 十二、优化limit操作
默认时limit操作仍然会执行整个查询,然后返回限定的行数。在有些情况下这种处理方式很浪费,因此可以通过设置下面的属性避免此行为。
<property>
<name>hive.limit.optimize.enable</name>
<value>true</value>
</property>
<property>
<name>hive.limit.row.max.size</name>
<value>100000</value>
</property>
<property>
<name>hive.limit.optimize.limit.file</name>
<value>10</value>
</property>
<property>
<name>hive.limit.optimize.fetch.max</name>
<value>50000</value>
</property>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
说明:
- hive.limit.optimize.enable:是否启用limit优化。当使用limit语句时,对源数据进行抽样。
- hive.limit.row.max.size:在使用limit做数据的子集查询时保证的最小行数据量。
- hive.limit.optimize.limit.file:在使用limit做数据子集查询时,采样的最大文件数。
- hive.limit.optimize.fetch.max:使用简单limit数据抽样时,允许的最大行数。
# 十三、分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所 有的数据文件。 Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。 在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率 会提高很多,所以我们需要把常常用在 WHERE 语句中的字段指定为表的分区字段。
# 13.1 创建分区表
在 Hive 中可以使用 PARTITIONED BY 子句创建分区表。表可以包含一个或多个分区列,程序会为分区列中的每个不同值组合创建单独的数据目录。下面的我们创建一张雇员表作为测试:
CREATE EXTERNAL TABLE emp_partition(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_partition';
2
3
4
5
6
7
8
9
10
11
12
# 13.2 指定分区导入
LOAD DATA LOCAL INPATH 'input/hive/partitions/file1'
INTO TABLE logs
PARTITION (dt='2001-01-01', country='GB');
2
3
# 13.3 显示分区信息
show partitions logs;
# 13.4 修复分区表
msck repair table order_created_partition;
# 13.5 添加分区
ALTER TABLE page_views ADD IF NOT EXISTS
PARTITION (dt=‘2013-09-09’, applicationtype=‘iPhone’) LOCATION ‘/somewhere/on/hdfs/data/iphone/current’
PARTITION (dt=‘2013-09-08’, applicationtype=‘iPhone’) LOCATION ‘/somewhere/on/hdfs/data/prev1/iphone’;
-- 增加多个分区
alter table dept_partition add partition(day='20200405') partition(day='20200406');
2
3
4
5
# 13.6 删除分区
ALTER TABLE log_messages DROP IF EXISTS PARTITION(year=2015,month=1,day=2);
-- 同时删除多个分区
alter table dept_partition drop partition (day='20200404'), partition(day='20200405');
2
3
# 13.7 查看分区表有多少分区
show partitions dept_partition;
# 13.8 分区限制查询
ALTER TABLE log_messages
PARTITION(year=2015,month=1,day=1)
ENABLE OFFLINE;
2
3
# 13.9 防止删除分区
ALTER TABLE log_messages
PARTITION(year=2015,month=1,day-1)
ENABLE NO_DROP;
2
3
# 13.10 修改某分区的文件格式
ALTER TABLE XXX PARTITION (EVENT_MONTH='2014-06') SET FILEFORMAT TEXTFILE;
# 13.11 动态分区
关系型数据库中,对分区表 Insert 数据时候,数据库自动会根据分区字段的值,将数据 插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition),只不过, 使用 Hive 的动态分区,需要进行相应的配置。
- 开启动态分区参数设置
-- 开启动态分区功能(默认 true,开启)
set hive.exec.dynamic.partition=true;
-- 设置为非严格模式(动态分区的模式,默认 strict,表示必须指定至少一个分区为 静态分区,nonstrict 模式表示允许所有的分区字段都可以使用动态分区。)
set hive.exec.dynamic.partition.mode=nonstrict;
-- 在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认 1000
set hive.exec.max.dynamic.partitions=1000;
-- 在每个执行 MR 的节点上,最大可以创建多少个动态分区。
-- 该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有 365 个值,那么该参数就需要设置成大于 365,如果使用默认值 100,则会报错。
set hive.exec.max.dynamic.partitions.pernode=100
-- 整个 MR Job 中,最大可以创建多少个 HDFS 文件。默认 100000
set hive.exec.max.created.files=100000
-- 当有空分区生成时,是否抛出异常。一般不需要设置。默认 false
set hive.error.on.empty.partition=false
-- 开启该参数的话,分区列会全局排序,使得reduce端每个分区只有一个文件写入,降低reduce的内存压力。
set hive.optimize.sort.dynamic.partition=true;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 案例实操
-- 创建目标分区表
hive (default)> create table dept_partition_dy(id int, name string)
partitioned by (loc int) row format delimited fields terminated by '\t';
-- 设置动态分区
hive (default)> set hive.exec.dynamic.partition.mode = nonstrict;
hive (default)> insert into table dept_partition_dy partition(loc) select
deptno, dname, loc from dept;
-- 查看目标分区表的分区情况
hive (default)> show partitions dept_partition;
2
3
4
5
6
7
8
9
# 十四、分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理 的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围 划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。分区针对的是数据的存储 路径,分桶针对的是数据文件。
# 14.1 创建分桶表
在 Hive 中,我们可以通过 CLUSTERED BY 指定分桶列,并通过 SORTED BY 指定桶中数据的排序参考列。下面为分桶表建表语句示例:
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照员工编号散列到四个 bucket 中
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_bucket';
2
3
4
5
6
7
8
9
10
11
12
# 14.2 加载数据到分桶表
这里直接使用 Load 语句向分桶表加载数据,数据时可以加载成功的,但是数据并不会分桶。
load data inpath '/read_state.csv' into table input_table;
这是由于分桶的实质是对指定字段做了 hash 散列然后存放到对应文件中,这意味着向分桶表中插入数据是必然要通过 MapReduce,且 Reducer 的数量必须等于分桶的数量。由于以上原因,分桶表的数据通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因为 CTAS 操作会触发 MapReduce。加载数据步骤如下:
# 1. 设置强制分桶
set hive.enforce.bucketing = true; --Hive 2.x 不需要这一步
在 Hive 0.x and 1.x 版本,必须使用设置 hive.enforce.bucketing = true,表示强制分桶,允许程序根据表结构自动选择正确数量的 Reducer 和 cluster by column 来进行分桶。
属性hive.enforce.bucketing = true与分区中的hive.exec.dynamic.partition = true属性类似,当我们启用该属性时,动态桶倒入会开启。
# 2. CTAS导入数据
INSERT INTO TABLE emp_bucket SELECT * FROM emp; --这里的 emp 表就是一张普通的雇员表
可以从执行日志看到 CTAS 触发 MapReduce 操作,且 Reducer 数量和建表时候指定 bucket 数量一致:
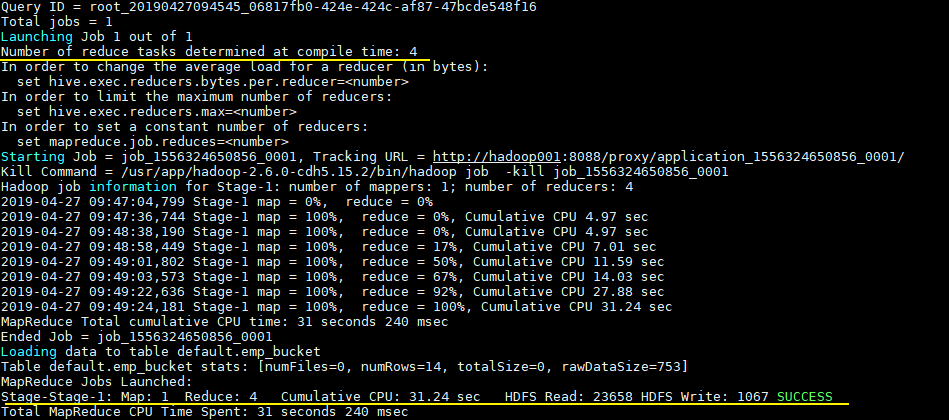
# 14.3 查询样本数据
1.返回1/4的桶的数据
SELECT * FROM bucketed_users TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
2.返回1/2的桶的数据
SELECT * FROM bucketed_users TABLESAMPLE(BUCKET 1 OUT OF 2 ON id);
3.使用rand() 函数对于没有划分成桶的表进行取样,即使只需要读取很小一部分样本,也要扫描整个输入数据集:
SELECT * FROM users TABLESAMPLE(BUCKET 1 OUT OF 4 ON rand());
# 14.4 指定桶大小
set mapred.reduce.tasks=64;
INSERT OVERWRITE TABLE t1
SELECT a,b,c FROM t2 CLUSTER BY b;
2
3
# 十六、CBO 优化
join 的时候表的顺序的关系:前面的表都会被加载到内存中。后面的表进行磁盘扫描
select a.*, b.*, c.* from a join b on a.id = b.id join c on a.id = c.id;
Hive 自 0.14.0 开始,加入了一项 "Cost based Optimizer" 来对 HQL 执行计划进行优化, 这个功能通过 "hive.cbo.enable" 来开启。在 Hive 1.1.0 之后,这个 feature 是默认开启的, 它可以 自动优化 HQL 中多个 Join 的顺序,并选择合适的 Join 算法。 CBO,成本优化器,代价最小的执行计划就是最好的执行计划。传统的数据库,成本优 化器做出最优化的执行计划是依据统计信息来计算的。 Hive 的成本优化器也一样,Hive 在提供最终执行前,优化每个查询的执行逻辑和物理 执行计划。这些优化工作是交给底层来完成的。根据查询成本执行进一步的优化,从而产生 潜在的不同决策:如何排序连接,执行哪种类型的连接,并度等等。 要使用基于成本的优化(也称为 CBO),请在查询开始设置以下参数:
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
2
3
4
# 十七、 谓词下推
将 SQL 语句中的 where 谓词逻辑都尽可能提前执行,减少下游处理的数据量。对应逻 辑优化器是 PredicatePushDown,配置项为 hive.optimize.ppd,默认为 true。
-- 打开谓词下推优化属性
hive (default)> set hive.optimize.ppd = true; #谓词下推,默认是 true
-- 查看先关联两张表,再用 where 条件过滤的执行计划
hive (default)> explain select o.id from bigtable b join bigtable o on o.id = b.id where o.id <= 10;
-- 查看子查询后,再关联表的执行计划
hive (default)> explain select b.id from bigtable b join (select id from bigtable where id <= 10) o on b.id = o.id;
2
3
4
5
6
# 十八、 大表、大表 SMB(Sort Merge Bucket Join) Join
- 创建大表
create table bigtable2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/bigtable' into table bigtable2;
2
3
4
5
6
7
8
9
10
- 测试大表直接 JOIN
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable a
join bigtable2 b
on a.id = b.id;
2
3
4
5
测试结果 Time taken: 72.289 seconds
- 创建分通表 1
create table bigtable_buck1(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/bigtable' into table
bigtable_buck1;
2
3
4
5
6
7
8
9
10
11
12
13
14
- 创建分通表 2 分桶数和第一张表的分桶数为倍数关系
create table bigtable_buck2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/
2
3
4
5
6
7
8
9
10
11
12
13
- 设置参数
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
2
3
- 测试
Time taken: 34.685 seconds
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
2
3
4
5
# 十五、常见错误及解决方案
# 15.1 JVM 堆内存溢出
描述:java.lang.OutOfMemoryError: Java heap space
解决:在 yarn-site.xml 中调整如下代码
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 15.2 orc格式存储的job无故报错
Caused by: java.lang.ClassCastException: org.apache.hadoop.io.LongWritable cannot be cast to org.apache.hadoop.io.IntWritable
set hive.vectorized.execution.enabled=false;
set hive.auto.convert.join=false;
2
# 十六、控制符
Control character (opens new window) C0 and C1 control codes (opens new window)
← 函数